
FileMakerで基本的なデータベースを作成するには、「テーブル」「フィールド」「レコード」「レイアウト」「スクリプト」の概念を習得する必要があります。
今回はテーブルとフィールド、そしてリレーションシップの基本的な解説です。
テーブル
「テーブル」の概要について
テーブルは、データを置いておく大枠の場所になります。
紙ベースのデータ管理だと、一般的に1枚1枚の書類をカテゴリーごとに分けたファイルにまとめておくのが一般的です。
例えば、
- 社員住所録
- 通勤届け
- 業務日誌
これらのカテゴリー分した1枚1枚の書類を、1冊の同じファイルに煩雑に収納したら、うまく整理できませんよね。目的の書類を後から探すのも大変になります。
したがって、カテゴリーごとにファイルを分けて収納しますね。
例えば、先ほどの例だと「社員住所録」「通勤届け」「業務日誌」という3冊のファイルができることになります。
FileMakerのテーブルは、例えればカテゴリーごとに分けて保存しておく「書類入れ(ファイルのようなもの)」という解釈もできます。
- 社員住所録というファイル(テーブル)
- 通勤届けというファイル(テーブル)
- 業務日誌というファイル(テーブル)
もう一つの方法を考えてみましょう。
上記の3冊のファイル方法をやめて、存在する全ての人数分ファイルを用意し、個人ごとのファイルを作成するという考え方もあります。それぞれの個人ファイルにインデックス(社員住所録・通勤届け・業務日誌などの見出し)をつけて、探しやすくするという管理方法もあります。
FileMakerのデータベースに例えると、社員の数だけテーブルを作成することになります。FileMakerでは、一つのファイルにいくつものテーブルを作成することが可能です。
したがって、1人1テーブルを作成することも可能です。
しかし、社員の人数分だけファイルを用意しなければならないのは、後に膨大な数の社員数になった際に、多くのファイルを準備しなければなりません。
数名の書類を管理するのであればそこまで問題は発生しませんが、社員数が何百人になるような場合、何百冊のファイルを準備しなければなりません。この方法ではスマートでありませんね。
仮に、膨大な社員数にならないような数名〜数十人のデータであり、今後そこまで増える見込みが無い場合、データベース化する必要がありません。
データーベース化することで有効な一例
- 数十〜数百件以上のデータになる場合
- 今後もデータの種類(書類)が増え続け、継続して保存しておく必要のあるデータである場合
- 後に、「検索」機能を使用して速やかに探し出したいデータである場合
- バックアップを頻回にとるような、データベースファイルのデータが重要な場合
上記のような場合は、データベース化するメリットがあるように思います。
話を戻しまして、個人の数だけテーブルを作成するのは現実的ではありません。
では、どのようにテーブルを作成したら良いのでしょう。
正解は前者の方になります。ざっくり、カテゴリーごとにテーブルを作成する方が良いでしょう。
なぜなら、データベースのメリットである「検索」などの機能は、テーブルの中に設定する「フィールド」という項目単位で行います。
すなわち、「社員住所録」のなかの、「氏名」というフィールドに、探したい社員名を入力してデータ検索などを行う訳です。
社員の数だけテーブルを作成したら、検索が行えなくなってしまいます。ですから、大きな枠組みとして、書類のカテゴリーごとにテーブルを作成するのが良いと考えます。
次は、さらに一工夫考えてみましょう。
テーブルを作成する際の工夫(リレーションシップ)を考慮する
- 社員住所録
- 通勤届け
- 業務日誌
上記3項目に共通するであろう項目があります。
それは、どの書類においても、同じ社内で使用するデータであれば、「氏名」「年齢」「生年月日」「性別」などは共通データです。
「社員住所録」「通勤届け」「業務日誌」どれをとっても、まず「氏名」という項目は絶対に重複しますね。
ここをスマートにデーターベースを作成していく方法として、「リレーションシップ」という方法があります。
初心者の方には、少し敷居が高いイメージがありますが、極めて重要です。整理して考えていきましょう。
「社員管理.fmp12」というFileMakerのファイルを一つ作成します。その中に、「社員マスタ」というテーブルを作成します。
「社員マスタ」のテーブルに最も基本的な項目として「IDフィールド」を作成しておきます。


「ID」のタイプは、「数字」にしておきます。
この「社員マスタ」テーブルに基本的な属性情報を入力するフィールドを次々に作成していきます。
「氏名」→フィールドタイプ「テキスト」
「性別」→フィールドタイプ「テキスト」
「年齢」→フィールドタイプ「数字」
「生年月日」→フィールドタイプ「日付」
「住所」→フィールドタイプ「テキスト」

フィールドとは
少し説明が前後してしまいましたが、フィールドについての簡単な解説をします。
フィールドは、テーブル上に設置する入力項目のことになります。
通勤届けというテーブルであれば、「氏名」「住所」「通勤方法」などの入力項目を設定します。これがフィールドになります。
フィールドの種類(タイプ)
FileMakerのフィールドには、どのようなデータを入力するのかを想定してあらかじめ幾つかのタイプが設定してあります。
- テキスト
- 数字
- 日付
- 時刻
- タイムスタンプ
- オブジェクト
- 計算
- 集計
一つの書類のなかには、様々な項目がありますね。住所録で例えば、「氏名」「性別」「生年月日」「年齢」「住所」などです。
この中でも、データの種類が異なることが伺えます。
フィールドタイプ「テキスト」に適した項目
例えば、「氏名」と「性別」と「住所」は文字、いわゆるテキストデータ(文字データ)になります。したがってフィールドタイプは「テキスト」になります。
フィールドタイプ「数値」に適した項目
「年齢」は、テキストデータではありますが、上記の項目と少し異なるのは、数値しか入力されることはありません。仮に年齢を「二十五歳」と入力するならば話は別ですが、一般的に「25」と入力することを仮定しています。そうすると、フィールドタイプはとりあえず「数字」を選択しておきます。
これは、例えばですが、のちに計算で利用する可能性がある場合、フィールドタイプを「数字」にしておいた方が良い場合があります。
「後に社員の平均年齢を出したい」なんてことがあった場合、FileMakerに計算機能を設定したフィールドを作成すると、平均年齢などを簡単に計算しデータ化できます。
また、年齢の若い順に並べ替え(ソート)をしたい場合、フィールドタイプを「数字」にしておくべきでしょう。
今回は詳しく説明しませんが、フィールドタイプ「計算」を利用すると、レコード内のデータの平均や合計、最高値、最低値などを表示させるフィールドを作成できます。
このように、後に計算してその結果を別のフィールドに表示させる必要があるかもしれない場合、フィールドタイプは「数値」にしておくべきでしょう。地味に重要です。
フィールドタイプ「日付」に適した項目
「生年月日」は、テキストデータではありますが、FileMakerには、フィールドタイプ「日付」というものがあります。
FileMakerでは、「0001 年 1 月 1 日から 4000 年 12 月 31 日」までの範囲の日付をサポートしています。
フィールドタイプ「日付」は、「数字」であったよう、計算にも使用できます。例えば、「A日付」-「B日付」=XX日みたいな計算です。
経過日数を追う可能性が考えられるデータが必要であれば、まずフィールドタイプ「日付」にしておいた方が良いでしょう。
話を戻して、「生年月日」ですが、フィールドタイプを「日付」にしておくと、「ドロップダウンカレンダー」という入力方法が使用できます。

キーボードで「2017/01/14」と入力しても良いのですが、入力する人間によっては、「ドロップダウンカレンダー」を使用すると視覚的な入力でき便利であるという利点があります。
もちろん、キーボードで「2017/01/14」と入力することも可能ですので、とりあえずフィールドタイプは「日付」にしておけば間違いないでしょう。
とりあえず、「社員マスタ」に設定するフィールドはここまでとしましょう。
リレーションシップについて
ここで、「社員マスタ」テーブルのデータを他のテーブルで活用する「リレーションシップ」という概念を解説します。
通勤届けテーブルの作成
社員マスタのデータを他のテーブルでも活用するために、事例として「通勤届け」というテーブルを作成します。

仮に、「通勤届け」テーブルに設定したいフィールド(項目)は、
- 氏名
- 性別
- 年齢
- 生年月日
- 住所
- 通勤方法
- 通勤にかかる所用時間
- 自宅から会社までの距離
であったとします。
お気づきになりましたか?青字で示した部分は、先程作成した「社員マスタ」テーブルに作成したフィールドと重複した項目です。したがって、そこのテーブルとリンク(繋げる)させることで社員マスタのデータを共有(活用)できるのです。
これがリレーションシップという概念です。
実践する前に、「通勤届け」テーブルに6〜8のフィールドを設定します。
そして、忘れてはならないのが、「社員マスタ」テーブルと同様に、「通勤届け」テーブルにも「ID」という数値フィールドを作成しておきます。

リレーションシップの設定
まず、データベースの管理画面からリレーションシップを選択します。
すると、先ほど作成した「社員マスタ」と「通勤届け」というテーブルが表示されます。
各テーブルの下には、作成したフィールドが表示されています。

今回は、「ID」というフィールドでリレーションシップを定義します。
簡単に説明すると、「社員マスタ」にあるデータは、他のリレーションシップを定義したテーブルでも使用できるようになる、ということです。つまり、表示であったり、編集であったりできるということです。
設定は簡単です。両者の「ID」フィールド同士をドラッグアンドドロップで繋ぐだけです。

これでリレーションシップが定義されました。

動作確認をします。
まず、「社員マスタ」のレイアウトを開きます。1レコード作成して、適当なデータを入力します。
「新規レコード」をクリックします。
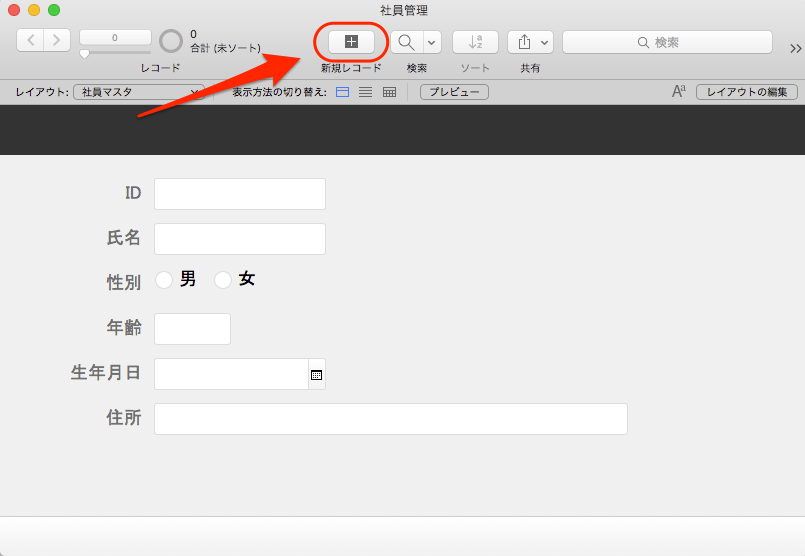
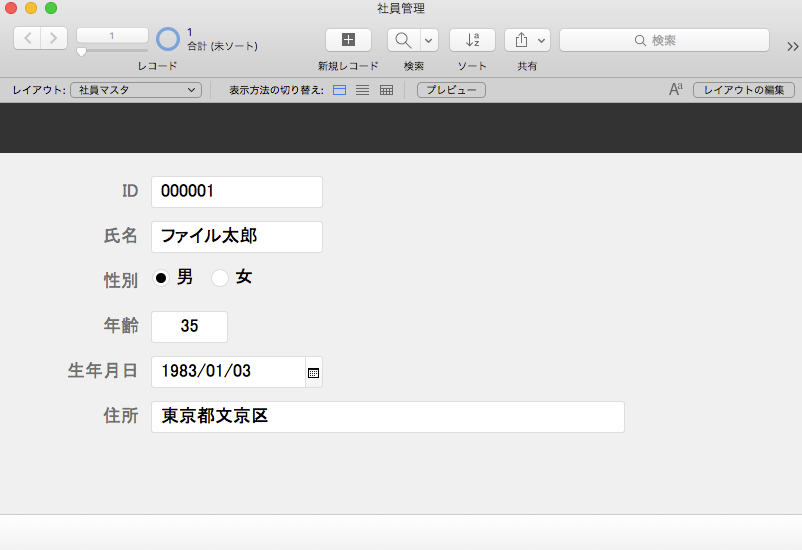
適当なデータを入力します。
次に、「通勤届け」レイアウトの設定を行います。
まずは、もともと「通勤届け」テーブルにあったフィールドを配置します。

続いて、「社員マスタ」のフィールドを設定していきます。
「フィールドピッカー」をクリックし、テーブルを「社員マスタ」へ切り替えます。

あとは、「ID」以外のフィールドをレイアウト内にドラッグアンドドロップして挿入します。

ここで、通勤届けの「ID」に先ほど社員マスタに入力したIDである「000001」を入力してみます。
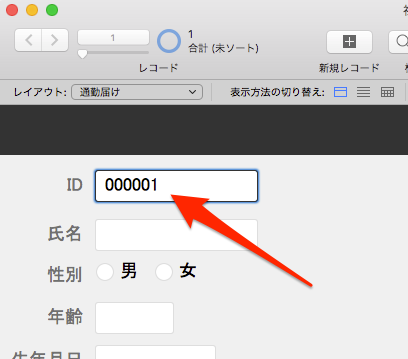
すると、氏名などのフィールドに、先ほどの社員マスタのデータが自動的に入力されました。

正確には、「通勤届け」テーブルからも「社員マスタ」テーブルのデータが表示(参照)されるようになった、ということです。
今回は、各テーブルの「ID」で紐付けを行っていますので、テーブル同士で、各IDフィールドの値が同一になった際に、リレーションシップを定義したテーブル同士のデータを表示できるようになります。
「社員マスタ」のように、起点になるデータには必ず「ID」フィールドを作成しておきましょう。そして、そのレコードごとに唯一の値を入力しておかなければなりません。
1人一つの固有(重複しない)の「ID」を振ることで、他のテーブルでも「ID」を起点にデータの共有ができるのです。
なお、フィールドの設定で、新規レコードを作成するたびに自動で重複しない値を挿入するようにしておけば間違いないでしょう。
新規レコードを作成するたびに重複しない「ID」を自動で作成

レコードが無い場合は、下記のように「000001」を指定します。
すでにレコードがある場合は、最終レコード数に1を足した値を指定します。
こうすることで、新規レコードを作成する度に、1づつ増えていくユニークなIDが自動的に作成されます。

